
并发与并行、进程和线程的概念、go的协程、channel
与其说是教程,更像是总结
一起学习![]()
并发与并行
并发只是在宏观上给人感觉有多个程序在同时运行,但在实际的单CPU系统中,每一时刻只有一个程序在运行,微观上这些程序是分时交替执行。
并行是将这些并发执行的程序分配到不同的CPU上处理,每个CPU用来处理一个程序,这样多个程序便可以实现同时执行。
知乎上高赞例子:
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。所以我认为它们最关键的点就是:是否是『同时』。
进程 线程 协程
进程:操作系统级别
一个进程好比是一个程序,它是资源分配的最小单位 。同一时刻执行的进程数不会超过核心数。不过如果问单核CPU能否运行多进程?答案又是肯定的。单核CPU也可以运行多进程,只不过不是同时的,而是极快地在进程间来回切换实现的多进程。
进程拥有自己的地址空间,全局变量,文件描述符,各种硬件等等资源。
操作系统通过调度CPU去执行进程
线程:操作系统级别
进程和进程之间相当于程序与程序之间的关系,线程与线程之间就相当于程序内的任务和任务之间的关系。所以线程是依赖于进程的,也称为 「微进程」 。它是程序执行过程中的最小单元。
进程是CPU资源分配的基本单位,线程是独立运行和独立调度的基本单位(CPU上真正运行的是线程)。
进程拥有自己的资源空间,一个进程包含若干个线程,线程与CPU资源分配无关,多个线程共享同一进程内的资源。
线程的调度与切换比进程快很多
协程:语言级别
协程,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
协程的调度,完全是由用户决定,无需锁的参与,并且是在一个线程内,自然成本最低,最快,当然缺点也就来了,那就是一个线程内不管你开了多少协程,始终无法真正利用多核CPU,无法做到真正的并发
Go的协程

开启一个协程
func main(){
go func(){
fmt.Println(”Hello“)
}()
}
不会有输出,因为协程还没开始,主线程就挂了,所以需要等待一下
time.Sleep(time.Second)
func main() {
for i := 0; i < 50; i++ { //传值可以避免闭包
go func(n int) {
fmt.Printf("%d ",n)
}(i)
}
time.Sleep(time.Second)
}
1 49 11 12 13 14 15 16 17 18 9 39 38 6 45 35 46 25 47 26 48 0 28 20 40 19 41 21 42 29 43 30 44 31 32 22 33 34 23 24 36 37 3 2 10 8 4 27 7 5
交出”控制权”
交出控制权前
func main() {
go func() { //子协程 //没来的及执行主进程结束
for i := 0; i < 5; i++ {
fmt.Println("go")
}
}()
for i := 0; i < 2; i++ { //默认先执行主进程主进程执行完毕
fmt.Println("hello")
}
}
hello
hello
交出控制权后
func main() {
go func() { //让子协程先执行
for i := 0; i < 5; i++ {
fmt.Println("go")
}
}()
for i := 0; i < 2; i++ {
//让出时间片,先让别的协议执行,它执行完,再回来执行此协程
runtime.Gosched()
fmt.Println("hello")
}
}
go
go
go
go
go
hello
hello
协程是双向的,双向的通道就是channel
Channel

channel 使用
func main() {
//定义一个双向channel
c := make(chan int)
//定义一个只读channel
//c1 := make(<-chan int, 1)
//定义一个只写channel
//c2 := make(chan<- int, 1)
//开一个goroutine来接收数据
go func() {
for {
n := <-c
fmt.Println("n =", n)
time.Sleep(time.Second*2)
}
}()
//先发送1,再发送2...
c <- 1
c <- 2
c <- 3
c <- 4
}
1
2
3
4
channel 作为参数传递
//Chan 作为返回值
func worker(id int, c chan int) {
for {
fmt.Printf("Worker %d, received %c\n",
id, <-c)
}
}
func chanDemo() {
var channels [10]chan int
//使用函数方式来接收
for i := 0; i < 10; i++ {
//初始化channels数组中的channel
channels[i] = make(chan int)
go worker(i, channels[i])
}
//发送数据
go func() {
for i := 0; i < 10; i++ {
channels[i] <- 'a' + i
}
for i := 0; i < 10; i++ {
channels[i] <- 'A' + i
}
}()
time.Sleep(time.Millisecond)
}
func main() {
chanDemo()
}
每次有不一样的输出,看CPU
Worker 9, received j
Worker 0, received a
Worker 0, received A
Worker 4, received e
Worker 1, received b
Worker 1, received B
Worker 3, received d
channel 作为返回值
func createWorker(id int) chan<- int {
c := make(chan int)
go func() {
for {
//<- 接收参数
fmt.Printf("Worker %d, received %c\n", id, <-c)
}
}()
return c
}
func main() {
var channels [10]chan<- int
//使用函数方式来接收
for i := 0; i < 10; i++ {
channels[i] = createWorker(i)
}
//发送数据
go func() {
for i := 0; i < 10; i++ {
channels[i] <- 'a' + i
}
for i := 0; i < 10; i++ {
channels[i] <- 'A' + i
}
}()
time.Sleep(time.Millisecond)
}
每次有不一样的输出,看CPU
Worker 4, received e
Worker 3, received d
Worker 1, received b
Worker 6, received g
Worker 9, received j
Worker 7, received h
Worker 5, received f
Worker 2, received c
Worker 8, received i
Worker 0, received a
Worker 0, received A
channel的符号可能会容易搞混,可以看看数据的流向来理解

channel 缓冲区
先看看为什么需要缓冲区?
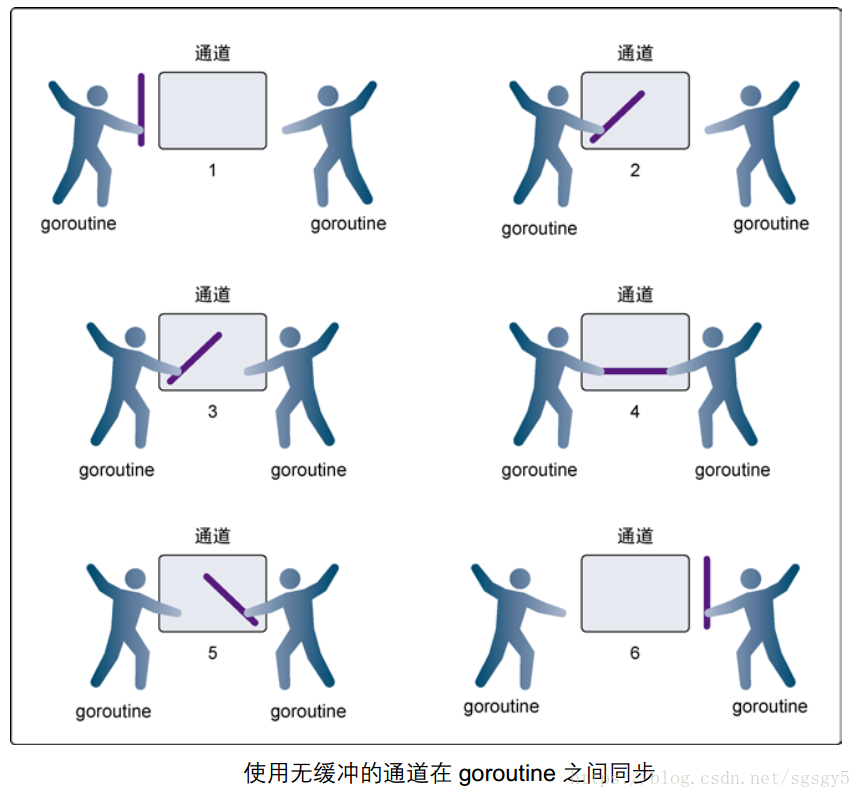
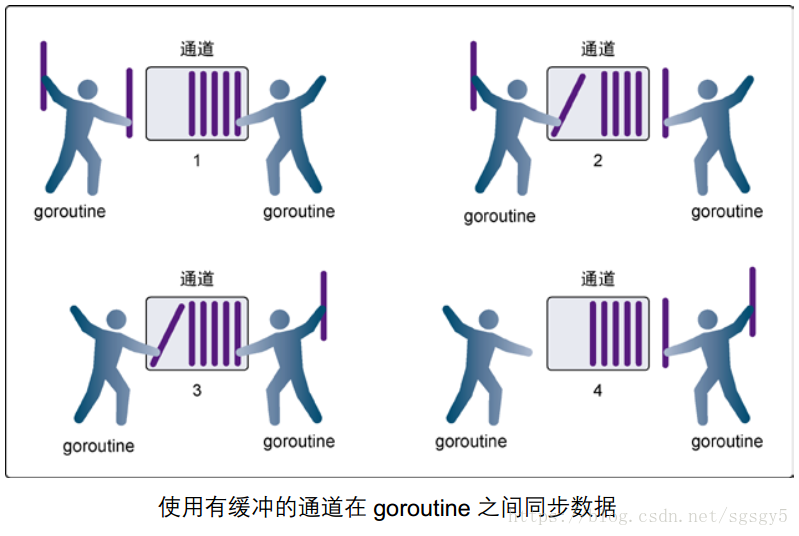
channel是协程间通信的”管道“,如果不设置缓冲区大小,默认是没有缓冲
现实生活中的管道都是有”缓冲区”的,水是从管道一端进一端出,如果出口阻塞了,也就没有继续接收
“管道”的缓冲也可以提高接收的效率
make源码
//...
// Channel: The channel's buffer is initialized with the specified
// buffer capacity. If zero, or the size is omitted, the channel is
// unbuffered.
func make(t Type, size ...IntegerType) Type
创建缓冲区
//建立Channel缓冲区
func bufferedChannel() {
//建立缓冲
c := make(chan int, 4)
c <- 'a'
c <- 'b'
c <- 'c'
c <- 'd'
time.Sleep(time.Millisecond)
}
如果设置小一点再接收
//建立Channel缓冲区
func bufferedChanne2() {
//建立缓冲
c := make(chan int, 2)
c <- 'a'
c <- 'b'
c <- 'c'
c <- 'd'
time.Sleep(time.Millisecond)
}
会死锁
fatal error: all goroutines are asleep - deadlock!
无缓冲
有缓冲
channel 关闭管道
channel是双向的,channel只能由发送方调用,表示发送结束。
close后还可以读取,但不可以发送所有接收的值都会非阻塞直接成功,返回channel元素的零值。
func main() {
ch := make(chan int, 5)
for i := 0; i < 5; i++ {
ch <- i
}
close(ch) // 关闭ch
for i := 0; i < 10; i++ {
e, ok := <-ch
fmt.Printf("%v, %v\n", e, ok)
if !ok {
break
}
}
}
最后会返回0,false
0, true
1, true
2, true
3, true
4, true
0, false
解决关闭channel后读取0问题的第二种方法
func worker(id int, c chan int) {
//解决关闭channel后读取0问题
for n := range c {
fmt.Printf("Worker %d, received %c\n",
id, n)
}
}
func main(){
//建立缓冲
c := make(chan int)
go worker(1, c)
go worker(2, c)
c <- 'a'
c <- 'b'
//close 后任然可以读取到 0
close(c)
time.Sleep(time.Millisecond)
}
Worker 2, received a
Worker 1, received b
channel 按顺序输出
捆绑个确认,这样就是发一个确认一个,同时一发一收保证顺序
goroutine和channel的配合,使用来控制多个协程的执行顺序;
type worker struct {
in chan int
done chan bool
}
func doWorker(id int, c chan int, done chan bool) {
//解决关闭channel后读取0问题 方法2
for n := range c {
//接收数据
fmt.Printf("Worker %d, received %c\n",
id, n)
//发送数据
done <- true
}
}
func createWorker(id int) worker {
w := worker{
in: make(chan int),
done: make(chan bool),
}
go doWorker(id, w.in, w.done)
return w
}
func main() {
var workers [10]worker
for i := 0; i < 10; i++ {
workers[i] = createWorker(i)
}
/**
同时一发一收保证顺序
*/
go func() {
//按顺序输出
for i := 0; i < 10; i++ {
//发送数据(byte)
workers[i].in <- 'a' + i
//接收数据(bool)
<-workers[i].done
}
for i := 0; i < 10; i++ {
workers[i].in <- 'A' + i
//接收数据
<-workers[i].done
}
}()
time.Sleep(time.Second)
}
Worker 0, received a
Worker 1, received b
Worker 2, received c
Worker 3, received d
Worker 4, received e
Worker 5, received f
Worker 6, received g
Worker 7, received h
Worker 8, received i
Worker 9, received j
Worker 0, received A
Worker 1, received B
Worker 2, received C
Worker 3, received D
Worker 4, received E
Worker 5, received F
Worker 6, received G
Worker 7, received H
Worker 8, received I
Worker 9, received J
错误的版本
type worker struct {
in chan int
done chan bool
}
func doWorker(id int, c chan int, done chan bool) {
for n := range c {
//接收数据
fmt.Printf("Worker %d, received %c\n",
id, n)
//发送数据
done <- true
}
}
func createWorker(id int) worker {
w := worker{
in: make(chan int),
done: make(chan bool),
}
go doWorker(id, w.in, w.done)
return w
}
func main() {
var workers [10]worker
for i := 0; i < 10; i++ {
workers[i] = createWorker(i)
}
//发送数据
for i, worker := range workers {
worker.in <- 'a' + i
}
for i, worker := range workers {
worker.in <- 'A' + i
}
for _, worker := range workers {
//接收数据
<-worker.done
<-worker.done
}
time.Sleep(time.Second)
}
会死锁
因为小写字母的的int发送和接收完了,而bool一直没人收,而紧接着大写字母又发和收了,它的bool发现缓冲区有”人”,但它又要发,就死锁了
Worker 2, received c
Worker 3, received d
Worker 1, received b
Worker 0, received a
Worker 5, received f
Worker 6, received g
Worker 7, received h
Worker 8, received i
Worker 9, received j
Worker 4, received e
fatal error: all goroutines are asleep - deadlock!
不完美的解决办法,没有顺序输出
因为不能及时收,所以无法保证顺序
func doWorker(id int, c chan int, done chan bool) {
for n := range c {
fmt.Printf("Worker %d, received %c\n",
id, n)
//发送数据
go func() {
done <- true
}()
}
}
顺序输出案例
有三个函数分别打印,“dog”,“cat”,“fish”,
要求每个函数起一个goroutine,请按照dog,cat,fish的顺序,打印四次,输出到控制台。
起了12个协程,控制每个协程的执行顺序,实现了4组dog,cat,fish的输出。
package main
import (
"fmt"
"sync"
)
func main(){
wg:=sync.WaitGroup{}
wg.Add(12) //打印四组,三个goroutine需要执行4次,3*4表示处于等待goroutine的数量
dogChan:=make(chan bool,1) //此处如果申明的是无缓冲的通道,那么会在16行代码处处于阻塞状态!原因:通道中无数据,向通道写数据,但无协程读取。
catChan:=make(chan bool)
fishChan:=make(chan bool)
dogChan<-true
for i:=0;i<4;i++{ //打印四组,三个goroutine需要执行4次
go dog(&wg,dogChan,catChan)
go cat(&wg,catChan,fishChan)
go fish(&wg,fishChan,dogChan)
}
wg.Wait()
fmt.Println("main finished!")
}
func dog(wg *sync.WaitGroup,dogChan chan bool,catChan chan bool){
if ok:=<-dogChan;ok {
fmt.Println("dog")
wg.Done()
catChan<-true
}
}
func cat(wg *sync.WaitGroup,catChan chan bool,fishChan chan bool){
if ok:=<-catChan;ok {
fmt.Println("cat")
wg.Done()
fishChan<-true
}
}
func fish(wg *sync.WaitGroup,fishChan chan bool,dogChan chan bool){
if ok:=<-fishChan;ok {
fmt.Println("fish")
wg.Done()
dogChan<-true
}
}
dog
cat
fish
dog
cat
fish
dog
cat
fish
dog
cat
fish
main finished!
3个协程,内部控制执行顺序
package main
import (
"fmt"
"sync"
)
func PrintDog(fishChan,dogChan chan bool){
defer wg.Done()
defer close(dogChan)
for i:= 0; i <4;i++{
<-fishChan
fmt.Println("dog ...")
dogChan<-true
}
}
func PrintCat(dogChan,catChan chan bool){
defer wg.Done()
defer close(catChan)
for i:= 0; i <4;i++{
<-dogChan
fmt.Println("cat ...")
catChan <- true
}
}
func PrintFish(catChan,fishChan chan bool){
defer wg.Done()
defer close(fishChan)
for i:= 0; i <4;i++{
<-catChan
fmt.Println("fish ...")
fishChan<-true
}
}
var wg sync.WaitGroup
func main() {
dogChan := make(chan bool,1)
catChan := make(chan bool,1)
fishChan := make(chan bool,1)
fishChan <- true
go PrintDog(fishChan,dogChan)
go PrintFish(catChan,fishChan)
go PrintCat(dogChan,catChan)
wg.Add(3)
wg.Wait()
}
内部代码执行的逻辑顺序图,通过bool来控制顺序

channel sync.WaitGroup()
sync.WaitGroup()是Go内置的等待函数,用法简单,需要wg.Add(20)注明需要开启的协程数量,使用完记得wg.Done()
type worker struct {
in chan int
wg *sync.WaitGroup
}
func doWorker(id int, c chan int, wg *sync.WaitGroup) {
for n := range c {
fmt.Printf("Worker %d, received %c\n",
id, n)
//发送数据
wg.Done()
}
}
func createWorker(id int, wg *sync.WaitGroup) worker {
w := worker{
in: make(chan int),
wg: wg,
}
go doWorker(id, w.in, wg)
return w
}
func main() {
var workers [10]worker
//使用系统自带的等待库
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
workers[i] = createWorker(i, &wg)
}
//任务数量
wg.Add(20)
//发送数据
for i, worker := range workers {
worker.in <- 'a' + i
}
for i, worker := range workers {
worker.in <- 'A' + i
}
wg.Wait()
}
可以看到是乱序的
Worker 6, received g
Worker 7, received h
Worker 5, received f
Worker 2, received c
Worker 4, received e
Worker 0, received a
Worker 8, received i
Worker 1, received b
Worker 3, received d
Worker 9, received j
Worker 9, received J
Worker 0, received A
Worker 1, received B
Worker 2, received C
Worker 3, received D
Worker 4, received E
Worker 5, received F
Worker 6, received G
Worker 7, received H
Worker 8, received I
非阻塞式并发
关键词select
func generator() chan int {
out := make(chan int)
go func() {
i := 0
for {
//随机时间发送
time.Sleep(time.Duration(rand.Intn(1500)) * time.Millisecond)
out <- i
i++
}
}()
return out
}
func main() {
//生成c1,c2
var c1, c2 = generator(), generator()
for {
//select 非阻塞式
select {
//接收c1的值
case n := <-c1:
fmt.Println("Received from c1: ", n)
//接收c2的值
case n := <-c2:
fmt.Println("Received from c2: ", n)
}
}
}
输出式c1和c2各输出各的,没有顺序
定时器
func generator() chan int {
out := make(chan int)
go func() {
i := 0
for {
//随机时间发送
time.Sleep(time.Duration(rand.Intn(2000)) * time.Millisecond)
out <- i
i++
}
}()
return out
}
func worker(id int, c chan int) {
for n := range c {
time.Sleep(1 * time.Second)//一秒钟收一次
fmt.Printf("Worker %d, received %d\n",
id, n)
}
}
//返回chan<-(只写入的channel)
func createWorker(id int) chan<- int {
c := make(chan int)
go worker(id, c)
return c
}
func main() {
//生成c1,c2
var c1, c2 = generator(), generator()
var worker = createWorker(0)
var values []int //保存产生的数据
tm := time.After(10 * time.Second) //结束程序时间
tick := time.Tick(time.Second) //定时任务处理,返回的是Time Channel
for {
var activeWork chan<- int
var activeValue int
//如果values切片中有元素
if len(values) > 0 {
//创建一个只能写入channel
activeWork = worker
//读取values中的第一位元素
activeValue = values[0]
}
select {
//给values加值
case n := <-c1:
values = append(values, n)
//给values加值
case n := <-c2:
values = append(values, n)
//获取切片
case activeWork <- activeValue:
//删除values切片中第一个元素
values = values[1:]
//超过了800毫秒没有回应(固定语法)
case <-time.After(800 * time.Millisecond):
fmt.Println("timeout")
//每秒中反馈一次切片长度
case <-tick:
fmt.Println("queue len= ", len(values))
//程序运行的时间计时器
case <-tm:
fmt.Println("bye")
return
}
}
}
timeout
queue len= 0
Worker 0, received 0
timeout
queue len= 2
Worker 0, received 0
queue len= 3
Worker 0, received 1
queue len= 5
Worker 0, received 1
queue len= 8
Worker 0, received 2
queue len= 9
Worker 0, received 3
queue len= 9
timeout
Worker 0, received 4
queue len= 9
Worker 0, received 2
queue len= 11
Worker 0, received 5
queue len= 11
bye
锁
package main
import (
"fmt"
"sync"
)
var total int
var wg sync.WaitGroup
func add() {
defer wg.Done()
for i := 0; i < 100000; i++ {
total += 1
}
}
func sub() {
defer wg.Done()
for i := 0; i < 100000; i++ {
total -= 1
}
}
func main() {
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Println(total) //理论上结果应该是0
}
72026
分析原因
func add(){
defer wg.Done()
for i := 0; i<100000; i++{
total += 1 => total = total + 1 //出错的根源
//原因如下
//因为底层加1分为三步 取值 加法 放回
//在这三步之中可能别的协程也在操作,就导致了资源竞争,导出出错
}
}
解决方法
锁会降低性能,能不用所就不使用锁,但为了保证用户读写一致性,会加读写锁🔒
绝大多数的Web系统来说 都是读多写少
1.都上互斥锁(解决同步问题),我锁住了你就不能锁
package main
import (
"fmt"
"sync"
)
var total int
var wg sync.WaitGroup
var lock sync.Mutex
func add(){
defer wg.Done()
for i := 0; i<100000; i++{
lock.Lock() //上锁
total += 1
lock.Unlock() //解锁
}
}
func sub() {
defer wg.Done()
for i := 0; i < 100000; i++ {
lock.Lock() //上锁
total -= 1
lock.Unlock()
}
}
func main() {
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Println(total) //理论上结果应该是0
}
2.读写锁
读和读之间不会产生影响,读和写之间才会有影响
读写锁
package main
import (
"fmt"
"sync"
"time"
)
//读写锁
var rwLock sync.RWMutex
var wg sync.WaitGroup
func read() {
defer wg.Done()
rwLock.RLock()//上读锁
fmt.Println("开始读取数据")
time.Sleep(time.Second * 3)
fmt.Println("读取成功")
rwLock.RUnlock()//解读锁
}
func write() {
defer wg.Done()
rwLock.Lock() //写锁是普通锁
fmt.Println("开始修改数据")
time.Sleep(time.Second * 10)
fmt.Println("修改成功")
rwLock.Unlock()
}
func main() {
wg.Add(5)
for i := 0; i < 5; i++ {
//可以同时读取
go read()
}
wg.Wait()
}
参考资料
Golang进程权限调度包runtime三大函数Gosched、Goexit、GOMAXPROCS