rocketmq消息队列
前言
mq(message queue)的使用场景
1.什么是mq?
消息队列是一种“先进先出”的数据结构

2.应用场景
其应用场景主要包含以下3个方面
- 应用解耦
系统的耦合性越高,容错性就越低。以电商应用为例,用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障或者因为升级等原因暂时不可用,都会造成下单操作异常,影响用户使用体验。
使用消息队列解耦合,系统的耦合性就会提高了。比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成。当物流系统回复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障。
- 流量削峰

应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮。有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提到系统的稳定性和用户体验。

一般情况,为了保证系统的稳定性,如果系统负载超过阈值,就会阻止用户请求,这会影响用户体验,而如果使用消息队列将请求缓存起来,等待系统处理完毕后通知用户下单完毕,这样总不能下单体验要好。
处于经济考量目的:
业务系统正常时段的QPS如果是1000,流量最高峰是10000,为了应对流量高峰配置高性能的服务器显然不划算,这时可以使用消息队列对峰值流量削峰
- 数据分发
通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可。
3.MQ的优点和缺点
优点:解耦、削峰、数据分发
缺点包含以下几点:
- 系统可用性降低 系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。 如何保证MQ的高可用?
- 系统复杂度提高 MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。 如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性?
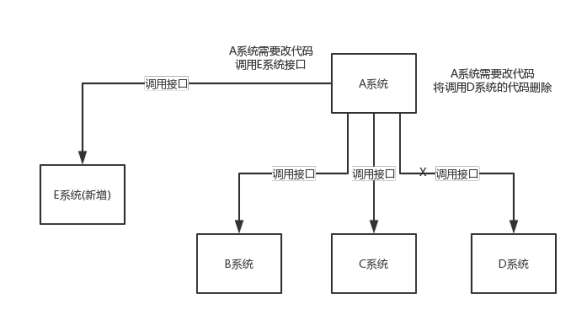
- 一致性问题 A系统处理完业务,通过MQ给B、C、D三个系统发消息数据,如果B系统、C系统处理成功,D系统处理失败。 如何保证消息数据处理的一致性?
4. mq技术选型

结论:
(1)中小型软件公司,建议选RabbitMQ.一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便。正所谓,成也萧何,败也萧何!他的弊端也在这里,虽然RabbitMQ是开源的,然而国内有几个能定制化开发erlang的程序员呢?所幸,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug,这点对于中小型公司来说十分重要。不考虑rocketmq和kafka的原因是,一方面中小型软件公司不如互联网公司,数据量没那么大,选消息中间件,应首选功能比较完备的,所以kafka排除。但是rocketmq已经交给apache管理,所以rocketmq的未来发展趋势看好。
(2)大型软件公司,根据具体使用在rocketMq和kafka之间二选一。一方面,大型软件公司,具备足够的资金搭建分布式环境,也具备足够大的数据量。针对rocketMQ,大型软件公司也可以抽出人手对rocketMQ进行定制化开发,毕竟国内有能力改JAVA源码的人,还是相当多的。至于kafka,根据业务场景选择,如果有日志采集功能,肯定是首选kafka了。具体该选哪个,看使用场景。
课程中选择rocketmq,基于两点考虑:
- 延迟消息简单高效
- 完善的事务消息功能
1.安装
1.1 下载文件
https://github.com/modouxiansheng/about-docker
1.2 配置idea中sftp


1.3 在服务器上解压安装
unzip RockertMQ.zip
cd RockertMQ
cd conf
vi broker.conf(修改ip)
cd ..
docker-compose up

检查状态
docker ps -a

访问
ip:8080

2. rocketmq的基本概念
- Producer:消息的发送者;举例:发信者
- Consumer:消息接收者;举例:收信者
- Broker:暂存和传输消息;举例:邮局(微信)
- NameServer:管理Broker;举例:各个邮局的管理机构
- Topic:区分消息的种类;一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息(公众号)
- Message Queue:相当于是Topic的分区;用于并行发送和接收消息
Name Server相当于服务中的consul,负责配置信息
Broker 负责真正的存储数据

3.recketmq的消息类型
3.1 按照发送的特点分:
3.1.1 同步发送
a.同步发送,线程阻塞,投递completes阻塞结束
b.如果发送失败,会在默认的超时时间3秒内进行重试,最多重试2次
c.投递completes不代表投递成功,要check SendResult.sendStatus来判断是否投递成功
d. SendResult里面有发送状态的枚举: SendStatus,同步的消息投递有一个状态返回值的
e. retry的实现原理:只有ack的SendStatus=SEND_OK才会停止retry
注意事项:发送同步消息且Ack为SEND_OK,只代表该消息成功的写入了MQ当中,并不代表该消息成功的被Consumer消费了
3.1.2 异步发送
a.异步调用的话,当前线程一定要等待异步线程回调结束再关闭producer啊,因为是异步的,不会阻塞,提前关闭producer会导致未回调链接就断开了
b.异步消息不retry,投递失败回调onException()方法,只有同步消息才会retry,源码参考DefaultMQProducerlmpl.class
c.异步发送一般用于链路耗时较长,对RT响应时间较为敏感的业务场景,例如用户视频上传后通知启动转码服务,转码完成后通知推送转码结果等。
3.1.3 单向发送
a.消息不可靠,性能高,只负责往服务器发送一条消息,不会重试也不关心是否发送成功
b.此方式发送消息的过程耗时非常短,一般在微秒级别

3.2 按照使用功能特点分:
3.2.1 普通消息(订阅)
普通消息是我们在业务开发中用到的最多的消息类型,生产者需要关注消息发送成功即可,消费者消费到消息即可,不需要保证消息的顺序,所以消息可以大规模并发地发送和消费,吞吐量很高,适合大部分场景。

3.2.2 顺序消息
顺序消息分为分区顺序消息和全局顺序消息,全局顺序消息比较容易理解,也就是哪条消息先进入,哪条消息就会先被消费,符合我们的FIFO,很多时候全局消息的实现代价很大,所以就出现了分区顺序消息。分区顺序消息的概念可以如下图所示:

我们通过对消息的key,进行hash,相同hash的消息会被分配到同一个分区里面,当然如果要做全局顺序消息,我们的分区只需要一个即可,所以全局顺序消息的代价是比较大的。
3.2.3 延时消息-订单超时库存归还
延迟的机制是在服务端实现的,也就是Broker收到了消息,但是经过一段时间以后才发送服务器按照1-N定义了如下级别“1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”;若要发送定时消息,在应用层初始化Message消息对象之后,调用Message.setDelayTimeLevel(int level)方法来设置延迟级别,按照序列取相应的延迟级别,例如level=2,则延迟为5s。只能从里面选择但它优化的很好。
实现原理: a.发送消息的时候如果消息设置了DelayTimeLevel,那么该消息会被丢到ScheduleMessageService.SCHEDULE_TOPIC这个Topic里面
b.根据DelayTimeLevel选择对应的queue
c.再把真实的topic和queue信息封装起来,set到msg里面
d.然后每个SCHEDULE_TOPIC_XXXX的每个DelayTimeLevelQueue,有定时任务去刷新,是否有待投递的消息e.每10s定时持久化发送进度
3.2.4 事务消息
文档 https://help.aliyun.com/document_detail/43348.html?
4.在本地配置Linux的python环境
4.1 Linux python操作rocketmq开发环境搭建
4.2 使用PyCharm工具



4.3 在虚拟机中加载需求的库
进入一个服务中
pip install -r requirements.txt -i https://pypi.douban.com/simple
先选择之前的

在选择回Linux下的
